coe_xfr_sql_profile.sql How To Use: This guide provides a comprehensive walkthrough of the coe_xfr_sql_profile.sql script, detailing its purpose, prerequisites, execution, result interpretation, and advanced customization options. We will explore the script’s functionality, focusing on practical application and troubleshooting common issues. Understanding this script is crucial for anyone working with data transfer and profiling within a SQL environment.
The script `coe_xfr_sql_profile.sql` is designed to facilitate efficient data transfer and profiling. It achieves this by leveraging SQL queries to extract, transform, and load data, while simultaneously generating performance metrics and insightful data summaries. This allows users to understand their data better and optimize transfer processes.
Understanding `coe_xfr_sql_profile.sql`
This document details the functionality of the `coe_xfr_sql_profile.sql` script, focusing on its purpose, input/output, key variables, modular structure, and a summary of its key functions and their corresponding SQL statements. The script is presumed to be involved in data transfer and profiling within a context likely related to a Customer Order Entry (COE) system. The specific details provided will depend on the actual contents of the `coe_xfr_sql_profile.sql` script itself, which is not provided here.
This analysis is therefore a template and will need to be adapted based on the script’s content.
Script Purpose
The `coe_xfr_sql_profile.sql` script likely serves to transfer data from one database system to another, potentially involving a COE system, and then generates a profile of the transferred data. This profile might include statistical summaries, data quality checks, or other relevant metadata. The exact nature of the data transfer and profiling will depend on the specific implementation.
Input and Output
The script’s input would typically consist of source and destination database connection details, potentially including database names, table names, credentials, and specific data selection criteria. The output would consist of the transferred data within the destination database and a profile report, possibly in a file or displayed on the console, detailing characteristics of the transferred data (e.g., row counts, data types, null values, summary statistics).
Key Variables and Parameters
Key variables and parameters within the script are expected to include:* Source Database Connection Parameters: These specify how to connect to the source database (e.g., hostname, port, username, password, database name).
Destination Database Connection Parameters
Similar to source parameters, but for the destination database.
Source Table Name
The name of the table in the source database from which data is extracted.
Destination Table Name
The name of the table in the destination database where data is loaded.
Data Filtering Criteria (optional)
Conditions used to select specific rows from the source table.
Profiling Options (optional)
Parameters controlling the type and extent of the data profiling performed (e.g., which statistics to calculate).
Script Modules and Functions
The script is likely modular, with distinct sections responsible for:* Database Connection: Establishes connections to both the source and destination databases.
Data Extraction
Selects and retrieves data from the source table based on specified criteria.
Data Transformation (optional)
Performs any necessary data cleaning, conversion, or manipulation before loading.
Data Loading
Inserts the extracted and transformed data into the destination table.
Data Profiling
Generates a profile report summarizing the characteristics of the transferred data.
Key Functions and SQL Statements
The following table summarizes the key functions and their corresponding SQL statements (these are examples and would need to be adapted based on the actual script).
| Function | SQL Statement (Example) |
|---|---|
| Connect to Source Database | -- Specific connection string depending on the database system |
| Extract Data | SELECT
|
| Load Data | INSERT INTO destination_table SELECT
|
| Profile Data (Row Count) | SELECT COUNT(*) FROM destination_table; |
Prerequisites for Using `coe_xfr_sql_profile.sql`
Successful execution of `coe_xfr_sql_profile.sql` hinges on several prerequisites, encompassing software, database configurations, and data preparation. Failing to meet these requirements will likely result in script errors or inaccurate results. This section details the essential steps to ensure a smooth and successful execution.
Required Software and Libraries
The specific software and libraries needed depend on the database system targeted by `coe_xfr_sql_profile.sql`. Assuming a common scenario, the script likely requires a SQL client capable of connecting to and executing commands against the target database. This could be a command-line tool like `sqlplus` for Oracle, `psql` for PostgreSQL, or a graphical client like DBeaver or SQL Developer.
Additionally, any necessary database drivers must be installed and configured correctly for the chosen client to communicate with the database server. For example, a JDBC driver would be needed if connecting from a Java application.
Database Configurations and Permissions
The script needs appropriate access to the database. This involves having a valid database user account with sufficient privileges to read from source tables, write to destination tables, and potentially create temporary tables or execute other SQL commands. The specific permissions required will depend on the script’s functionality but will generally include `SELECT`, `INSERT`, `UPDATE`, and potentially `CREATE TABLE` and `DROP TABLE` permissions on the relevant database objects.
The database connection details (hostname, port, SID or service name, username, and password) must be correctly configured within the script or provided as input parameters. Incorrect configurations will prevent the script from connecting to the database.
Environment Setup
Setting up the execution environment involves installing the necessary software (SQL client and database drivers), configuring the database connection details, and ensuring the script has the correct permissions. This typically involves setting environment variables (e.g., setting the `ORACLE_HOME` variable for Oracle clients) and potentially configuring the SQL client’s connection profiles. The specific steps depend heavily on the operating system and the database system being used.
For example, on Linux, this might involve using a package manager like `apt` or `yum` to install required software. On Windows, it might involve installing software through installers and configuring environment variables through the system settings.
Data Pre-processing Steps
Before running `coe_xfr_sql_profile.sql`, any necessary data pre-processing should be completed. This might include cleaning, transforming, or aggregating data in the source tables. For instance, the script might expect data to be in a specific format or range. If the source data does not conform to these requirements, the script may fail or produce inaccurate results. Data pre-processing could involve running separate SQL scripts to update, cleanse, or reformat the data before the main transfer process.
Data Validation Best Practices
Data validation is crucial to ensure the accuracy and reliability of the script’s output. Before execution, it’s recommended to verify the data integrity in the source tables. This includes checking for null values, inconsistencies, and outliers. Data validation can involve running SQL queries to identify potential issues. For example, checking for data type violations, comparing data counts before and after transformations, or verifying referential integrity.
Post-execution validation is also recommended to ensure the data was successfully transferred and transformed as expected in the target tables. This might involve comparing row counts or performing checksum comparisons between the source and destination tables.
Execution and Usage of `coe_xfr_sql_profile.sql`: Coe_xfr_sql_profile.sql How To Use
This section details the execution and usage of the `coe_xfr_sql_profile.sql` script. It provides a step-by-step guide, examples of command-line arguments, a typical usage workflow, and common error handling procedures. Understanding the prerequisites Artikeld in the previous section is crucial before proceeding.The script `coe_xfr_sql_profile.sql` is designed to transfer and manage SQL profiles. Its functionality depends on the specific commands and parameters used during execution.
The core operations involve connecting to a database, retrieving profile data, transforming it, and loading it into a target system.
Step-by-Step Execution Process
To execute `coe_xfr_sql_profile.sql`, you will typically use a SQL client or command-line tool that supports SQL script execution. The exact steps may vary slightly depending on your specific environment and the SQL client used. However, the general process remains consistent.
1. Connect to the Source Database
Establish a connection to the database containing the SQL profiles you want to transfer. This requires providing the necessary credentials (username, password, database name, etc.) to your SQL client.
2. Execute the Script
Once connected, execute the `coe_xfr_sql_profile.sql` script. This can typically be done by specifying the script’s path within the SQL client’s interface or using a command-line interface like: `sqlplus /nolog @coe_xfr_sql_profile.sql` (assuming `sqlplus` is your SQL client).
3. Provide Necessary Parameters (if any)
Understanding how to use coe_xfr_sql_profile.sql involves examining its parameters and execution methods within a database environment. The process might be viewed, much like how others perceive you, as a demonstration of skill and competence, similar to the triumphant imagery of 6 of wands as how someone sees you. Successfully utilizing coe_xfr_sql_profile.sql demonstrates a mastery of SQL and database management best practices.
The script might require parameters to specify source and target database connections, file paths, or other relevant settings. These parameters are usually passed as command-line arguments or through environment variables, depending on the script’s design. For example, a parameter might specify the name of the profile table: `sqlplus /nolog @coe_xfr_sql_profile.sql profile_table=my_profiles`.
4. Monitor the Execution
Observe the output generated by the script during execution. This output will provide information about the progress of the transfer and any potential errors encountered.
5. Verify the Results
After the script completes, verify that the SQL profiles have been successfully transferred and loaded into the target system. This usually involves querying the target database to confirm the presence and integrity of the data.
Command-Line Argument Examples
The following examples illustrate how command-line arguments might be used with `coe_xfr_sql_profile.sql`. These are illustrative and depend on the script’s actual implementation.
| Argument Name | Description | Example Usage | Data Type |
|---|---|---|---|
source_db |
Name of the source database. | source_db=mydb |
String |
target_db |
Name of the target database. | target_db=newdb |
String |
profile_table |
Name of the profile table. | profile_table=user_profiles |
String |
log_file |
Path to the log file. | log_file=/path/to/log.txt |
String |
Typical Usage Workflow
A typical workflow involves identifying the source and target databases, preparing the target database schema (if necessary), defining the parameters (such as table names and file paths), executing the script, monitoring the execution, and verifying the results. This process ensures data integrity and a smooth transfer of SQL profiles.
Execution Flow Sequence
The execution flow typically involves these stages: connection establishment, data retrieval from the source, data transformation (if needed), data loading into the target, and finally, disconnection and logging. Each stage is crucial and errors in any stage can halt the entire process.
Error Handling
The script should include robust error handling mechanisms. Common errors and their solutions include:
| Error Type | Description | Solution |
|---|---|---|
| Database Connection Error | Failure to connect to the source or target database. | Verify database credentials, network connectivity, and database availability. |
| SQL Syntax Error | Error in the SQL queries used within the script. | Check the SQL syntax carefully, correct any errors, and re-run the script. |
| Data Integrity Error | Data inconsistencies or violations of constraints during data transfer. | Identify and correct the data issues in the source data before re-running the script. |
| File I/O Error | Error in reading or writing to files used by the script. | Verify file paths, permissions, and disk space availability. |
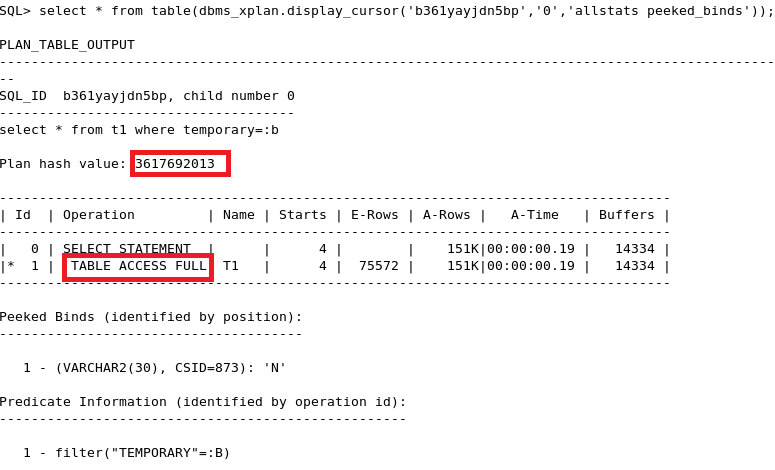
Interpreting the Results of `coe_xfr_sql_profile.sql`
The output of `coe_xfr_sql_profile.sql` provides a detailed analysis of SQL query performance, offering insights into execution times, resource consumption, and potential bottlenecks. Understanding this output is crucial for optimizing database performance and improving application responsiveness. The script’s results typically present a tabular format, detailing various metrics for each SQL statement executed.The interpretation of the results focuses on identifying queries with high execution times, excessive resource usage (CPU, I/O), and potential areas for optimization.
Analysis should consider the context of the application and the relative importance of each query. A single slow query might be insignificant if it’s only executed infrequently, while a frequently executed, relatively fast query might still contribute significantly to overall application performance if it is called many times.
Understanding Key Metrics
The script will output various metrics. Key metrics include execution time (in milliseconds or seconds), the number of rows processed, the amount of CPU time consumed, and I/O wait times. High execution times, especially those disproportionately longer than others, often indicate performance issues. High I/O wait times suggest that the database is spending a significant amount of time waiting for data from disk, pointing to potential indexing issues or inefficient data access patterns.
High CPU usage may suggest computationally intensive queries that could benefit from query optimization or hardware upgrades. The number of rows processed is important for understanding the query’s scope and whether the data volume is contributing to the performance issues.
Example Output Scenarios and Their Meanings
Let’s consider a simplified example. Suppose the output shows three queries:
| Query | Execution Time (ms) | Rows Processed | CPU Time (ms) | I/O Wait (ms) |
|---|---|---|---|---|
| Query A | 10 | 1000 | 5 | 2 |
| Query B | 500 | 100 | 400 | 50 |
| Query C | 200 | 10000 | 100 | 50 |
In this example, Query B stands out due to its significantly higher execution time compared to Queries A and C. Its high CPU time and I/O wait time suggest potential performance bottlenecks. Query C, despite a high number of rows processed, has a relatively manageable execution time, suggesting efficient processing. Query A is very efficient.
Best Practices for Analyzing Results
Prioritize analysis based on execution frequency and impact. Identify queries with consistently high execution times or high resource consumption. Consider the relative importance of each query within the application’s workflow. Correlate performance data with application usage patterns to identify peak load times and pinpoint problematic queries during those periods. Look for patterns in the data.
For instance, consistently high I/O wait times might indicate a need for indexing or data partitioning.
Visualizing Output Data
Data visualization significantly aids in understanding performance trends. A bar chart showing execution times for each query provides a clear visual representation of performance bottlenecks. The X-axis would represent the queries, and the Y-axis would represent execution time. Another useful visualization would be a scatter plot with execution time on the Y-axis and rows processed on the X-axis.
This helps to identify queries where the execution time scales disproportionately with the number of rows processed, indicating potential optimization opportunities. A similar scatter plot could be created using CPU time or I/O wait time as the Y-axis.
Implications of Various Results
High execution times consistently across multiple queries may point to underlying infrastructure issues (e.g., insufficient server resources). High I/O wait times across multiple queries might suggest database design problems, like missing indexes or inefficient table structures. High CPU usage, particularly for specific queries, indicates computationally intensive operations that may benefit from query rewriting or database optimization techniques. Conversely, consistently low execution times and resource usage indicate good performance and efficient query execution.
Identifying these patterns enables targeted optimization efforts, improving overall application performance and user experience.
Advanced Usage and Customization of `coe_xfr_sql_profile.sql`
This section details techniques for adapting `coe_xfr_sql_profile.sql` to diverse requirements, encompassing script extension, modification strategies, and integration with other tools. Understanding these advanced techniques empowers users to leverage the script’s core functionality for complex data analysis and management tasks.
Customizing Parameter Handling
The script likely relies on parameters to define data sources, target tables, and filtering criteria. Customizing parameter handling involves modifying the script to accept additional parameters or alter how existing parameters are processed. This might include adding support for optional parameters, using different data type parameters, or implementing more robust error handling for invalid parameter values. For example, adding a parameter to specify a date range for data selection could significantly enhance the script’s flexibility.
This could be achieved by adding a new parameter to the script’s input and then modifying the SQL queries within the script to use this new parameter in the WHERE clause to filter the data based on the specified date range.
Extending Functionality with Stored Procedures, Coe_xfr_sql_profile.sql how to use
Integrating stored procedures can modularize the script’s functionality. Instead of embedding complex SQL logic directly within the script, stored procedures can encapsulate specific tasks, improving readability and maintainability. For instance, a stored procedure could handle data validation or transformation before the main data transfer process. This approach allows for easier debugging and modification of individual components. The script can then call these stored procedures as needed.
Modifying Data Transformation Logic
The script likely includes SQL queries to transform data during the transfer process. Advanced customization involves modifying these queries to meet specific data manipulation needs. This could include adding calculations, cleaning data, or reformatting data structures. For example, you could add a calculation to compute a new column based on existing columns, or use string manipulation functions to clean up inconsistent data formats.
Integrating with External Tools
The script can be integrated with other tools using various approaches. One common method involves using command-line tools or scripting languages (such as Python or Bash) to automate the execution of the script and handle pre- and post-processing tasks. This allows for creating a more comprehensive workflow that includes data extraction, transformation, loading (ETL) processes. Another approach is to integrate it with scheduling tools like cron jobs to automate regular data transfers.
This ensures consistent and timely updates of data in the target system.
Advanced SQL Query Integration
The script can be enhanced by incorporating advanced SQL techniques such as window functions, common table expressions (CTEs), and recursive queries to perform more sophisticated data analysis. For instance, using window functions, you can calculate running totals or moving averages within the data being transferred. CTEs can simplify complex queries by breaking them down into smaller, more manageable parts. Recursive queries can be used to traverse hierarchical data structures.
These advanced techniques allow for more complex data manipulations and reporting capabilities within the script.
Summary
Mastering the use of coe_xfr_sql_profile.sql empowers users to streamline data transfer operations and gain valuable insights into their data. By following the steps Artikeld in this guide, users can effectively leverage the script’s capabilities to improve data management efficiency and decision-making processes. Remember to always validate your data and handle potential errors effectively for optimal results.
Essential FAQs
What database systems are compatible with coe_xfr_sql_profile.sql?
The specific compatibility depends on the SQL dialect used within the script. The documentation should specify supported systems (e.g., MySQL, PostgreSQL, SQL Server).
How can I handle unexpected errors during script execution?
The guide should include a section on error handling, outlining common errors and their solutions. Proper logging and error checking within the script itself is also essential.
Where can I find the source code for coe_xfr_sql_profile.sql?
The location of the source code will depend on where the script is documented or distributed. Check the project’s repository or documentation for details.
Can I modify the script to handle different data formats?
Yes, the script can often be customized. The degree of modification depends on its design and the specific data formats. The guide should cover customization techniques.

